

 Andriy Andrunevchyn
Andriy Andrunevchyn
Some time ago I described how we migrated from SVN to GIT. As usual when somebody migrates from one tool to another, also they bring their previous experience (good or bad). So we did the same. We used the following approach  Everybody developed on their branches and then merged on the dev branch, that branch we use for deploying on the dev server and testing some features that we were not able to check on the local machine. Then all changes during the current Sprint were pushed to qa branch and deployed on qa server where QA engineers tested features. Before release, we announced a code freeze for a day just to run regression testing. Once regression was completed we merged from the qa branch to the prod branch, created a release tag, and deployed it on the prod server. We used Jenkins with separate jobs for dev/qa/prod environments. The dev/QA/Operation team had corresponding access only to required jobs hence everything was secure and strict. Such a setup worked pretty fine for us because:
Everybody developed on their branches and then merged on the dev branch, that branch we use for deploying on the dev server and testing some features that we were not able to check on the local machine. Then all changes during the current Sprint were pushed to qa branch and deployed on qa server where QA engineers tested features. Before release, we announced a code freeze for a day just to run regression testing. Once regression was completed we merged from the qa branch to the prod branch, created a release tag, and deployed it on the prod server. We used Jenkins with separate jobs for dev/qa/prod environments. The dev/QA/Operation team had corresponding access only to required jobs hence everything was secure and strict. Such a setup worked pretty fine for us because:
- we had a small dev team
- we had a good QA team close to the dev team
- we deployed to QA often and tested quickly
- we included a small amount of features in a release
- we delivered good quality and had almost no issues with regression
- we didn’t develop different versions simultaneously
New Project
But then we started another kind of project… we were short on time and budget so we
- increased the dev team but didn’t increase qa team
- included on sprint plenty of features (deadlines required to release more staff and faster)
- weren’t allowed to run regression on each sprint because of the time limit
- got longer regression test period but rare
- got much more issues on regression
- got more requests to hotfix something on the prod
So with the existing git process described above we faced the next issue – from time to time, we required two “qa-like” branches and then heavy conflicts on merging to prod branch. The only thing we wanted to keep was Jenkins with separated jobs for dev/qa/prod versions of source code and secure deployment procedure.
New Approach
I tried finding help on Facebook(Ukrainian only). As a result of 161 comments we built a new git procedure 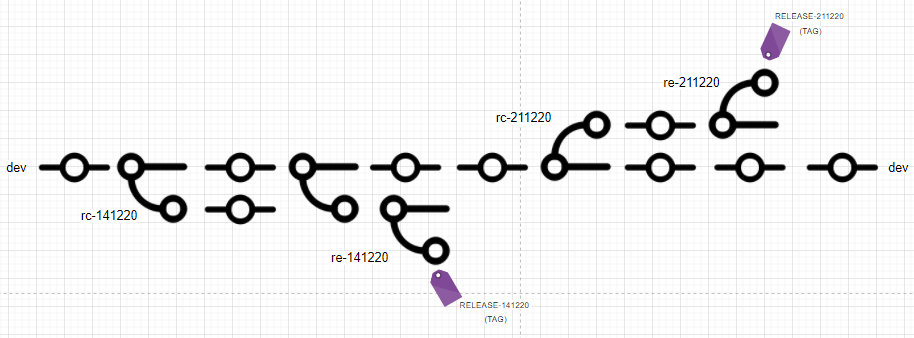 We have dev as the default branch. On the first day of Sprint, we create a new release candidate branch with the strict pattern “rc-{expected release date}“. Those rc- branches we use for deploying on the QA environment. Our Jenkins recognizes pattern rc- and suggests only them for deployment on the QA server. During Sprint once or twice per day we merge changes on the qa branch and then deploy. Two days before release we announced a code freeze only on the QA branch. In case the QA team finds some issue DEV team fixes it on the dev branch and cherry-picks it to the QA branch. As soon as the rc-* branch is tested we create a release branch with the naming “re-{expected release date}”. Jenkins job for production recognizes only branches with name re-. After production deployment we run smoke testing, create release tags, and delete outdated rc- and re- branches (usually we keep the last rs- branch and two last re-* branches). Dev, all rc-/re- branches and release tags are GitLab protected just prevent removing branch/tag by mistake. With the new approach, we could easily develop two versions simultaneously or deliver hotfixes without the burden of merging different branches. I hope this article will be useful for you. If you have some suggestions or comments don’t hesitate to let us know.
We have dev as the default branch. On the first day of Sprint, we create a new release candidate branch with the strict pattern “rc-{expected release date}“. Those rc- branches we use for deploying on the QA environment. Our Jenkins recognizes pattern rc- and suggests only them for deployment on the QA server. During Sprint once or twice per day we merge changes on the qa branch and then deploy. Two days before release we announced a code freeze only on the QA branch. In case the QA team finds some issue DEV team fixes it on the dev branch and cherry-picks it to the QA branch. As soon as the rc-* branch is tested we create a release branch with the naming “re-{expected release date}”. Jenkins job for production recognizes only branches with name re-. After production deployment we run smoke testing, create release tags, and delete outdated rc- and re- branches (usually we keep the last rs- branch and two last re-* branches). Dev, all rc-/re- branches and release tags are GitLab protected just prevent removing branch/tag by mistake. With the new approach, we could easily develop two versions simultaneously or deliver hotfixes without the burden of merging different branches. I hope this article will be useful for you. If you have some suggestions or comments don’t hesitate to let us know.
